Ending the Sidecar Civil War: How Pod-Level Resource Managers Change the Game ⚙️
Kubernetes v1.36 Pod-Level Resource Managers reduce NUMA latency, optimize sidecar-heavy workloads, and improve AI infrastructure performance.
The team at DevOps Inside knows that if GKE Pod Snapshots were the “Save States” for our AI infrastructure that we discussed recently, then Kubernetes v1.36 is the ultimate “Home Renovation.”
We’ve spent weeks fixing the 100 reasons our clusters cry and navigating the “AI Productivity Paradox,” but now the orchestrator itself is changing the rules of the game.
Until now, Kubernetes treated containers in a Pod like strangers sharing a cramped apartment. Everyone fought for the same CPU cycles and memory channels.
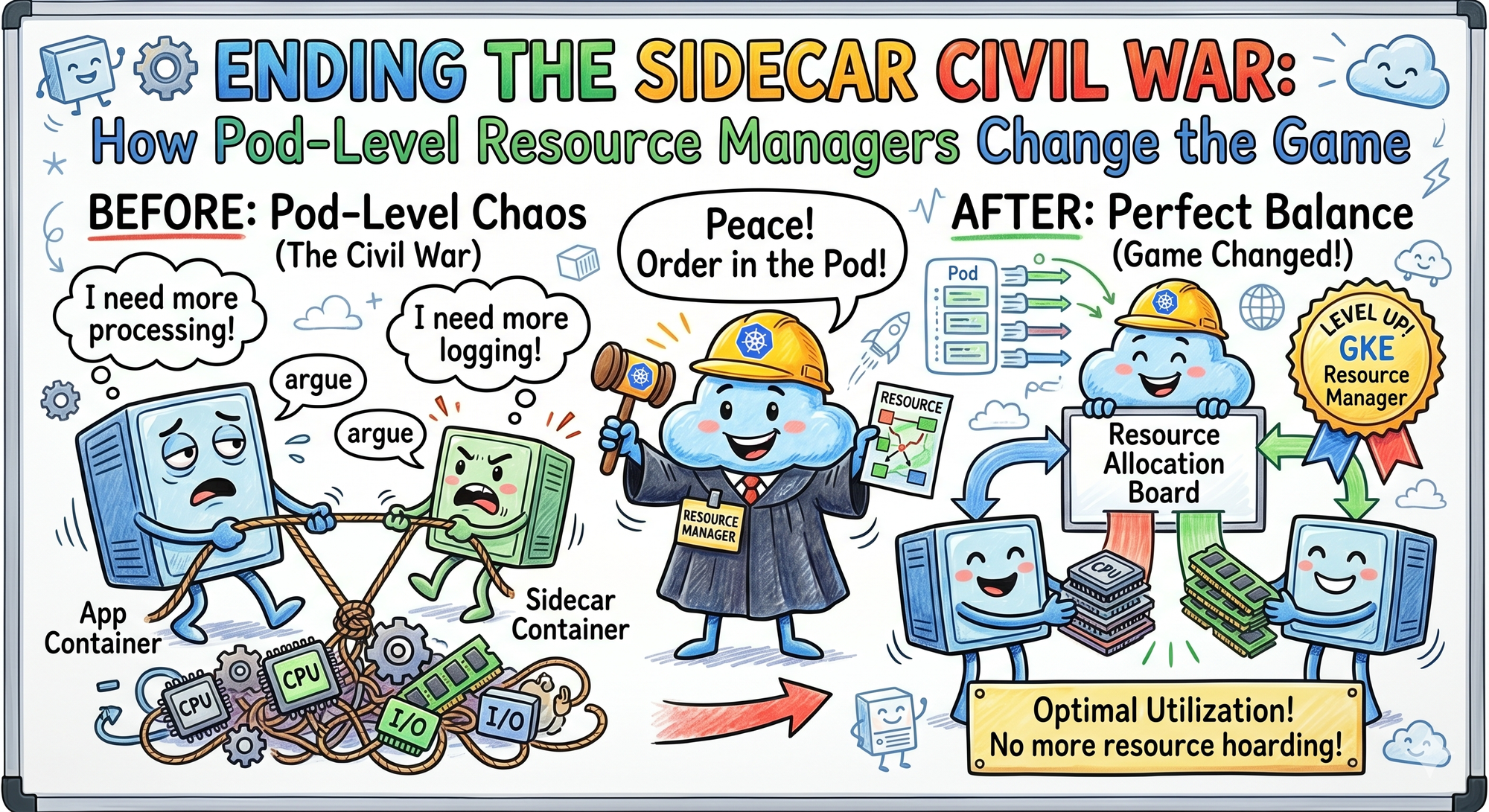
But with the introduction of Pod-Level Resource Managers, the Pod is finally being treated like a single, cohesive unit.
Following our “From Pipelines to Prompts” series, it’s time to look at how Kubernetes is fixing the “Sidecar Civil War.” ⚔️
🧠 Ending the Sidecar Civil War
In the SRE world, we’ve been living with a lie.
We tell ourselves that because we put a Service Mesh sidecar, a logging agent, and a security scanner in the same Pod, they’ll play nice.
The Reality?
They do not.
They fight.
Your high-performance AI runtime might be pinned to one CPU socket (NUMA node), while your observability sidecar is pulling data from a memory bank on the opposite side of the motherboard.
This “Topology Mismatch” creates a hidden latency tax that slows down your inference and quietly inflates your cloud bill. 💸
🔄 The “Pod-Aware” Evolution
Before v1.36, the Kubelet managed resources at the container level.
It was granular, but it was blind to the bigger picture.
If you had five containers in a Pod, the Kubelet made five independent decisions.
Pod-Level Resource Managers flip the script.
Kubernetes now looks at the Pod’s total requirements, including your AI runtime, sidecars, and init containers, and makes a unified topology decision.
🧩 NUMA Alignment
It ensures every container in the Pod is mapped to the same physical CPU socket and memory bus.
⚡ CPU Pinning
No more context-switching chaos where your app and sidecar constantly jump across CPU cores.
📦 Reduced Fragmentation
By making Pod-level decisions, Kubernetes stops leaving tiny holes of unusable resources scattered across nodes.
🤖 The AI Edge: Feeding the 70B Beast
We recently discussed how 75% of code is now AI-generated and how we’re scaling massive models using snapshots.
But those models are hungry.
🖥️ HPC and AI Workloads
For distributed training or low-latency inference, every nanosecond spent crossing a NUMA boundary is wasted performance.
Pod-level management ensures your GPU-bound processes are not being choked by a security agent that decided to sit on a “far” CPU core.
📊 Predictive Placement
We are already seeing early experiments where AI-driven schedulers use Pod-level metrics to predict which hardware topology will provide the best price-to-performance ratio for a specific model architecture.
That is where Kubernetes starts becoming less of an orchestrator and more of an infrastructure strategist.
⚠️ The SRE Reality Check
This is not just a “flip-the-switch” update.
To truly benefit from Pod-Level Resource Managers, your DevOps mindset needs to evolve, too.
🔧 Topology Manager Policy
You need to ensure your Kubelet is configured with a restricted or single-numa-node policy to force proper alignment.
📉 Sidecar Sizing
If your sidecar becomes too heavy, it can force the entire Pod onto a larger and more expensive hardware footprint simply to satisfy topology constraints.
🏗️ Hardware Heterogeneity
This feature shines on high-core-count machines.
If you are running tiny 2-core nodes, you are probably not going to see the magic.
This is built for the “Big Iron” side of the cloud. 🚀
🛰️ The Interactive SRE Challenge
Open your favorite observability tool:
- Datadog
- Grafana
- Pixie
Now look at a Pod running multiple sidecars.
Compare the P99 tail latency of the application with the sidecar enabled versus disabled.
If you notice a significant gap, there is a good chance you are dealing with NUMA fragmentation.
So here’s the real question:
Are you still managing containers as isolated islands, or are you finally ready to treat the Pod like a unified machine? ⚙️
🚀 The Verdict
Kubernetes v1.36 is moving us closer to bare-metal performance without sacrificing the flexibility of the cloud.
By making the orchestrator topology-aware, Kubernetes is finally addressing the hidden resource wastage that has plagued complex, sidecar-heavy architectures for years.
And honestly?
It was overdue.💬
💬Quick Question: Does your current node setup support NUMA-aware scheduling, or are your packets still taking the scenic route across the motherboard?
Let’s talk hardware in the comments.
"Turns out the biggest bottleneck in cloud-native infrastructure was not Kubernetes. It was containers fighting like siblings over the same CPU socket."