100x Faster than a GPU: The Rise of Hardwired AI Infrastructure
Are we paying a hidden GPU tax for every AI system we build? Discover why hardwired AI could become the next evolution of immutable infrastructure.

In the world of DevOps, we have a love affair with Immutable Infrastructure. We hate drift. We hate "snowflake" servers. We want our containers and VMs to be exactly what we defined in code, with zero deviation.
But there is one part of our stack that is still a massive, power-hungry snowflake: the GPU.
Right now, we are all paying a "GPU Tax." We spend billions on H100s, not because they are the most efficient way to run a model, but because they are the only flexible way. We treat LLMs like heavy software packages being loaded into RAM. And that "loading" is exactly where the tax hits us - in the form of the HBM (High Bandwidth Memory) Bottleneck.
But what if we treated the AI model not as software, but as the hardware itself?
Enter ChatJimmy: The Speed of Silicon
If you haven't visited chatjimmy.ai yet, prepare to be disoriented.

Most of us are used to the "streaming" effect of AI - the little cursor blinking as it thinks and slowly spits out words. That lag is the sound of data being shuttled between memory and compute.
ChatJimmy doesn't stream. It just arrives.
Built by the team at Taalas, ChatJimmy runs on the HC1 chip, a custom ASIC where the Llama 3.1 8B model isn't loaded into memory - it is etched into the silicon logic gates.
The "Magic" Numbers:
- Tokens per second: 15,000 to 16,000+ (For context, a high-end GPU usually hits 100–200).
- Response Time: Often under 0.05 seconds.
- Power: 10x less than a GPU setup.
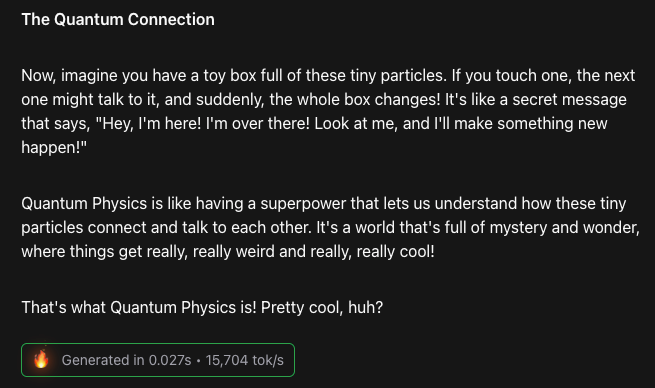
The UI looks deceptively simple. You type: "Explain Quantum Physics to a 5-year-old." The moment you hit Enter, the entire page is full of text. No typing animation. Just the result. At the bottom, a tiny badge reads: Generated in 0.027s @ 15,704 tok/s.
Yes, notice the time and the tokens per second.
The DevOps Parallel: Hardware as an Immutable Artifact
Why does this matter to us in SRE and DevOps? Because "Hardwired AI" is the ultimate evolution of the Immutable Infrastructure pattern.
- Zero Configuration Drift: In a GPU-based world, you deal with CUDA versions, driver mismatches, and VRAM fragmentation. In a Hardwired world, the model is the chip. You can't "misconfigure" the weights. There is no drift.
- Predictable Latency: On a shared GPU cluster, latency is a rollercoaster. On an ASIC like the HC1, the path the electrons take is fixed. Your P99 latency is essentially your P100. It’s the most deterministic compute we’ve ever seen.
- The "Disposable" Hardware Model: Just as we treat containers as disposable, Taalas suggests we treat chips as disposable. Don't upgrade the software; swap the chip. When a better model comes out, you swap a $20 ASIC that runs at 10x the speed of a $30k GPU.
Why 16,000 Tok/s Changes Everything
You might ask: "Do I really need an AI to talk that fast? I can't even read that fast."
You can't, but your Agentic Workflows can.
Imagine a DevOps Agent that needs to scan 10,000 lines of logs, correlate them with three different runbooks, and propose a fix. On a GPU, that "reasoning loop" might take 30 seconds - too slow for a real-time incident. On ChatJimmy-class hardware, that entire loop happens in under a second.
Final Thought: Breaking the Monopoly
The GPU Tax was the price we paid for flexibility during the "Experimental Era" of AI. But as we move into the "Production Era," we need the stability and efficiency of hardwired silicon.
ChatJimmy isn't just a fast chatbot. It’s a preview of a world where AI is as cheap and ubiquitous as a transistor, and where our infrastructure is truly, finally, immutable - all the way down to the silicon.
Want to see the future of SRE? Stop waiting for your tokens to stream and go see the magic at chatjimmy.ai.