MLOps vs DevOps: Key Strategies for Enterprise AI Success
MLOps vs DevOps: What’s the difference? Discover how enterprises scale AI with data pipelines, model monitoring, and strategies that turn experiments into value.
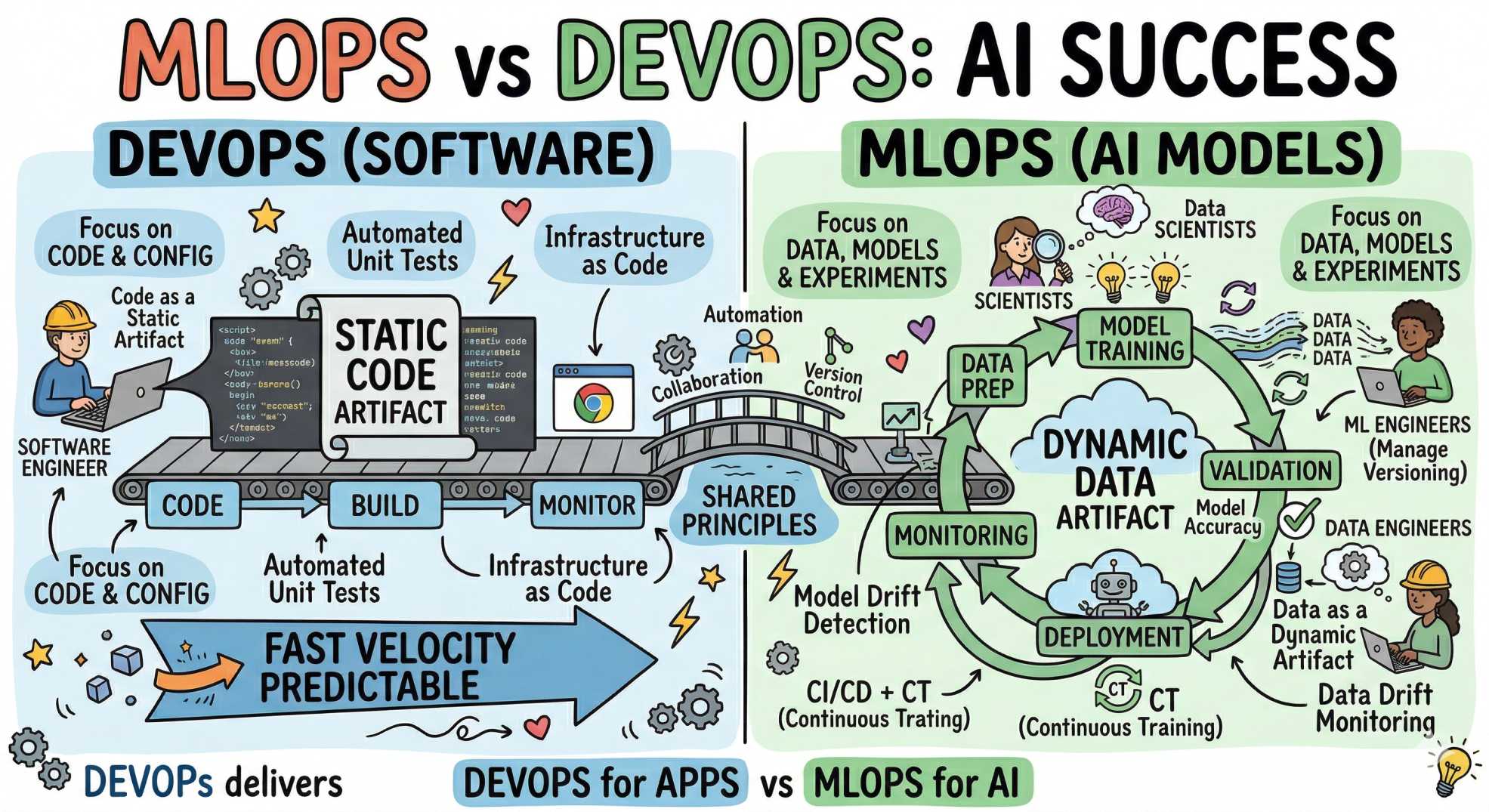
Welcome to the jungle of enterprise AI, where models roam, data grows like wild vines, and teams try to ship intelligence without accidentally launching a paperweight 🚀🤖. On devopsinside.com, we love making messy tech feel a little less chaotic and a lot more fun. In this post, we’ll walk through the difference between MLOps and DevOps, why both matter, and the practical strategies enterprises need to turn ML experiments into repeatable, reliable value.
Why MLOps is not just "DevOps for models."
At first glance, MLOps and DevOps sound like cousins, and they are. Both demand automation, version control, testing, and observability. But models introduce new flavors of complexity:
- Models decay over time as data shifts.
- Training requires heavy data orchestration and compute.
- Data and model drift are operational risks, not just bugs.
- Explainability, fairness, and regulatory compliance are often necessary.
So while DevOps gives us essential patterns (CI/CD, IaC, logging), MLOps extends those patterns to manage data, training, model evaluation, and continuous retraining. Think of DevOps as the engine, and MLOps as the navigation and fuel system that keeps the engine useful when the road changes.
Main differences: MLOps vs DevOps (quick comparison)
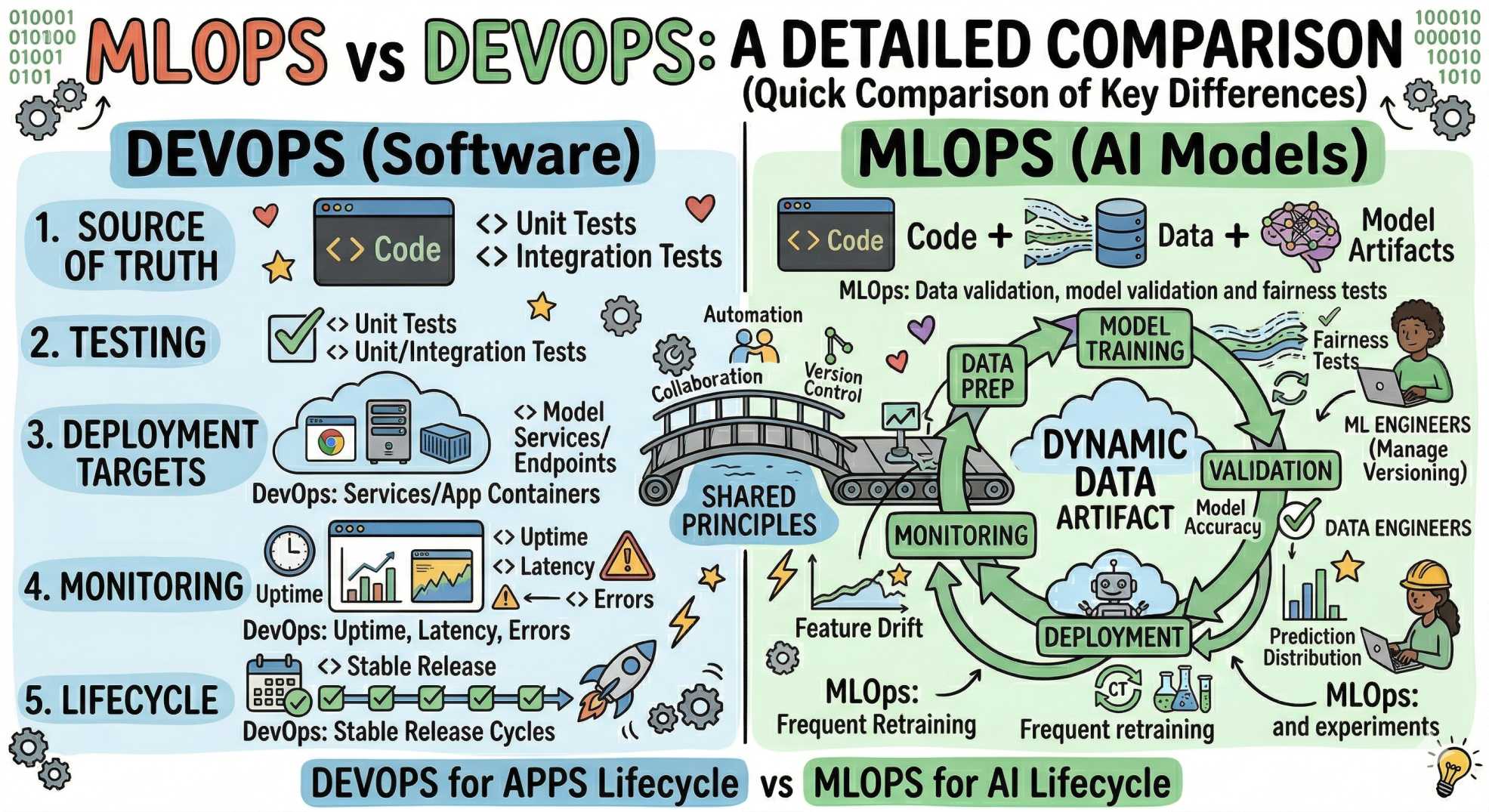
- Source of truth: DevOps: code. MLOps: code + data + model artifacts.
- Testing: DevOps: unit/integration tests. MLOps: data validation, model validation, and fairness tests.
- Deployment targets: DevOps: services/app containers. MLOps: model serving endpoints, batch scoring jobs, edge devices.
- Monitoring: DevOps: uptime, latency, errors. MLOps: model accuracy, prediction distribution, feature drift.
- Lifecycle: DevOps: stable release cycles. MLOps: frequent retraining and experiments.
Core components of a successful MLOps platform
An enterprise-ready MLOps stack supports the entire ML lifecycle from data ingestion to model retirement. Here's what to prioritize:
- Data versioning and lineage: Know which data produced which model and why.
- Feature stores: Serve consistent features in training and production.
- Model registry: Store, version, and stage models (dev → staging → prod).
- Automated pipelines: Reproducible ETL, training, testing, and deployment.
- Model monitoring: Track accuracy, drift, latency, and downstream impact.
- Governance & explainability: Audit trails, lineage, and interpretable outputs for compliance.
- Scalable infra & cost management: Autoscaling, spot instances, and thoughtful resource allocation.
DevOps foundations that still matter (and why)
MLOps doesn’t replace DevOps; it builds on it. These are the fundamentals you should keep or strengthen:
- CI/CD for code and infra: automated pipelines are a must.
- Infrastructure as Code (IaC): reproducible environments for training and serving.
- Observability: logs, metrics, and distributed tracing to debug production problems.
- Security: access control for data, models, and endpoints.
- Culture of collaboration: shared ownership across Data Science, ML Engineering, and DevOps.
Key strategies for enterprise AI success (actionable)
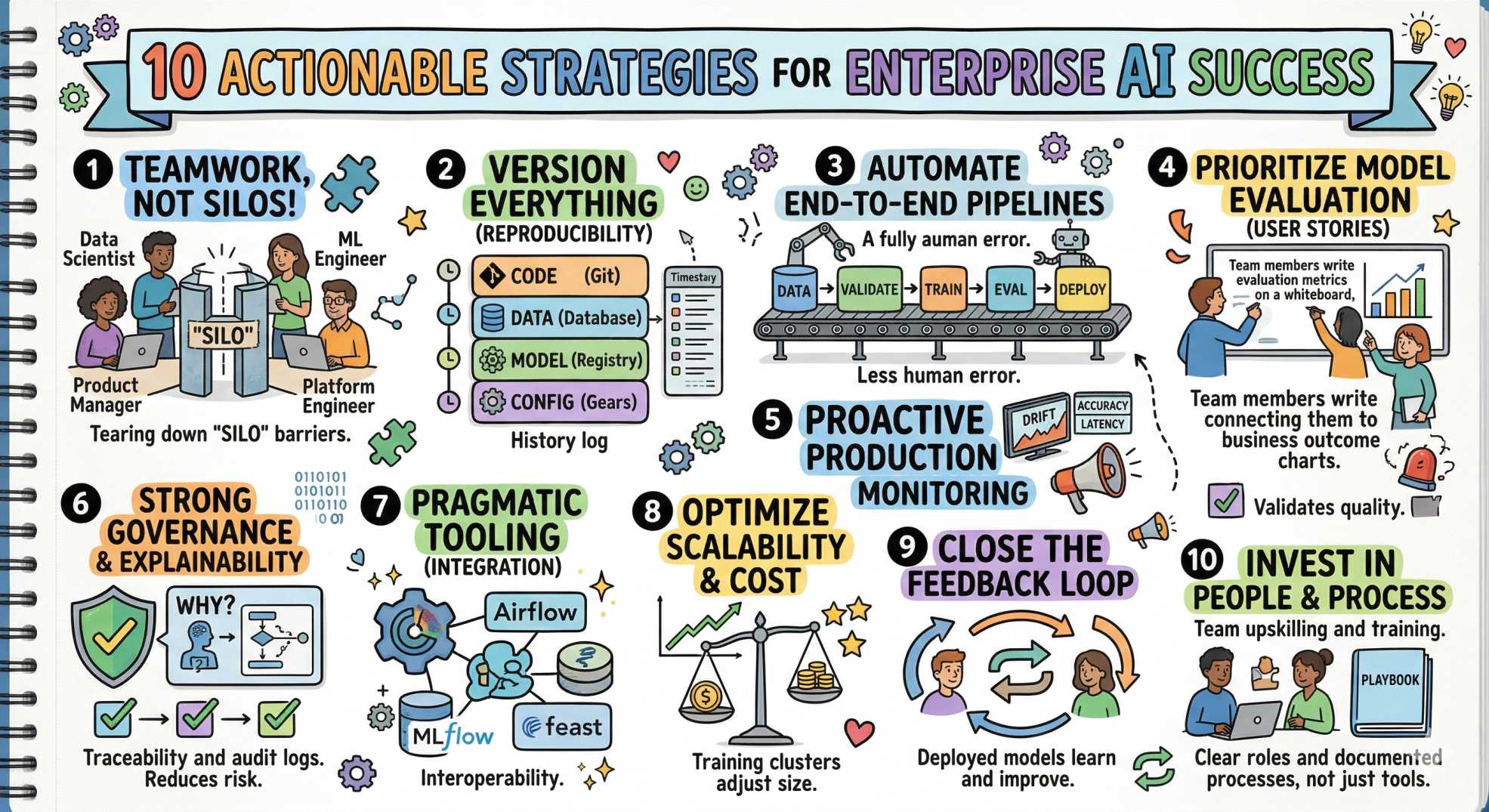
Ready for the good stuff? Here are practical strategies that take you from experiments to dependable AI products, sprinkled with a little cheer 😄.
1) Build cross-functional teams, not silos
Set up small, product-focused teams combining data scientists, ML engineers, platform engineers, and product managers. Give them a mission and the autonomy to iterate. This reduces handoffs and miscommunication (and saves countless Slack threads). 🧩
2) Version everything: data, models, code, configs
Make reproducibility non-negotiable:
- Use Git for code and IaC.
- Use data versioning tools or object stores with metadata for datasets.
- Use a model registry (MLflow, Seldon, or built-in platform registries) for model artifacts.
3) Automate the ML pipeline end-to-end
Automation reduces human error and ensures consistent behavior. Your pipeline should include:
- Data validation and schema checks
- Training jobs with deterministic configuration
- Automated model evaluation & quality gates
- Deployment (canary/blue-green) with rollback
4) Treat model evaluation like a user story, not an afterthought
Define clear evaluation metrics tied to business outcomes. Use validation suites that include:
- Performance metrics (accuracy, F1, ROC-AUC)
- Business KPIs (conversion, LTV uplift, cost reduction)
- Robustness checks (adversarial inputs, noisy data)
- Fairness and bias tests
5) Monitor models in production, proactively
Monitoring should watch multiple signals:
- Prediction quality (when ground truth is available)
- Statistical drift (feature distribution changes)
- Service metrics (latency, errors)
- Business impact metrics
Set automated alerts and, when feasible, automated triggers for retraining or rollback when thresholds are breached. 🚨
6) Implement strong governance and explainability
Especially in regulated industries, you need:
- Traceability: Which dataset and code produced a model?
- Explainability: why did the model make a prediction?
- Approval workflows and audit logs
This reduces legal and reputational risk and makes stakeholders more comfortable adopting AI.
7) Use the right tooling: pragmatic over trendy
Too many tools can create chaos. Choose a focused set that integrates well with your environment:
- Orchestration: Airflow, Kubeflow Pipelines, Prefect
- Model registry: MLflow, Tecton, or built-in cloud registry
- Serving: KFServing/Seldon, TensorFlow Serving, TorchServe, or cloud-managed endpoints
- Feature store: Feast, Tecton, Hopsworks
Start small and standardize; you can expand later. Remember: interoperability beats shiny-new-tool FOMO. ✨
8) Optimize for scalability and cost
Training and inference are resource-hungry. Balance performance and cost with approaches like:
- Autoscaling inference clusters
- Spot/preemptible instances for training
- Batch vs real-time inference trade-offs
- Model quantization or distillation for edge/latency-constrained deployments
9) Close the feedback loop, productize learning
Use production signals to inform retraining and feature improvements. Instrument the data pipeline to capture labeled outcomes and user feedback. This turns deployed models into learning systems, not static artifacts. 🔁
10) Invest in people, and process; tools alone won’t save you
Tools are accelerants, not magic. Invest in:
- Training and upskilling for teams
- Documented processes and playbooks
- Clear roles and ownership for data, models, and infra
Common pitfalls and how to avoid them (short list)
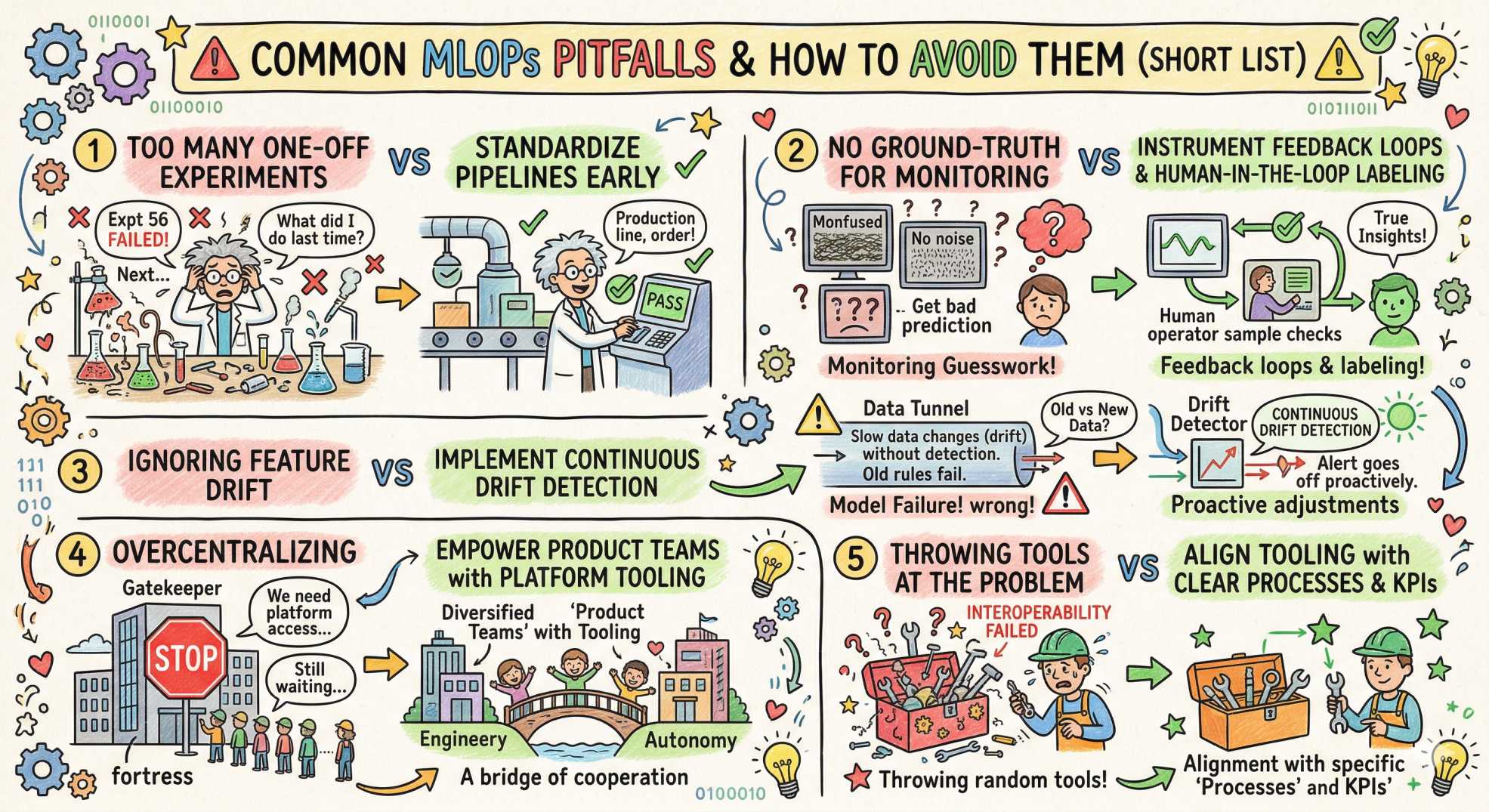
- Too many one-off experiments: standardize pipelines early.
- No ground-truth for monitoring: instrument feedback loops and human-in-the-loop labeling where needed.
- Ignoring feature drift: implement continuous drift detection.
- Overcentralizing: empower product teams with platform tooling, not gatekeeping.
- Throwing tools at the problem: align tooling with clear processes and KPIs.
Quick checklist: MLOps vs DevOps action items
- Implement CI/CD for code and pipelines
- Version datasets and model artifacts
- Establish a model registry and staging workflow
- Set up monitoring for both infra and model quality
- Create governance policies and audit trails
- Run cost & capacity planning for training and inference
- Define retraining triggers and automation
Final thoughts: make AI repeatable, not accidental
In short, DevOps gives you reliable delivery, and MLOps gives you reliable intelligence. Pair them, and you get an enterprise that can ship AI with confidence, systems that adapt, measure, and improve over time. It’s less about replacing DevOps and more about extending DevOps principles to include data, models, and the human workflows around them.
Whether you’re shipping a fraud detector, a recommendation system, or a predictive maintenance model, the recipe is the same: cross-functional teams, automation, versioning, monitoring, governance, and a pragmatic set of tools. Add a sprinkle of curiosity and a dash of patience, and you’ll turn experiments into outcomes. 😄
If you enjoyed this rundown and want more practical guides from the intersection of DevOps and AI, swing by devopsinside.com. We love talking about pipelines, platforms, and the human side of delivery. Want a template checklist or pipeline diagram specific to your stack? Drop a comment. let’s ship smarter together! 🚢✨
“Anyone can deploy a model. The real game is keeping it smart after it hits production.”