Behind Every Reliable AI Agent Is Boring Engineering (Here’s the Playbook)
Why do most AI agents fail in production? Discover the “boring engineering” playbook behind reliable AI—monitoring, guardrails, and DevOps best practices.

Why most AI agent prototypes look impressive, but almost none survive production ⚙️
Building an AI agent demo today is surprisingly easy. You connect a large language model, add a few prompts and tools, and within hours, you have something that looks intelligent. It summarizes logs, suggests fixes, and answers questions. Everyone in the room feels impressed.
Then you try running the same system in production.
Suddenly, the cracks appear. The agent misses obvious issues, latency increases, outputs become inconsistent, and costs rise. What felt magical in a demo quickly becomes unreliable in real environments. That’s when teams realize a hard truth: a working prototype is not the same as a working product.
Turning an AI experiment into something teams can depend on during real incidents requires engineering discipline, not just smarter prompts. Reliability comes from systems, processes, and measurement. Below are the practices that actually help an AI DevOps agent move from prototype to production. 📊
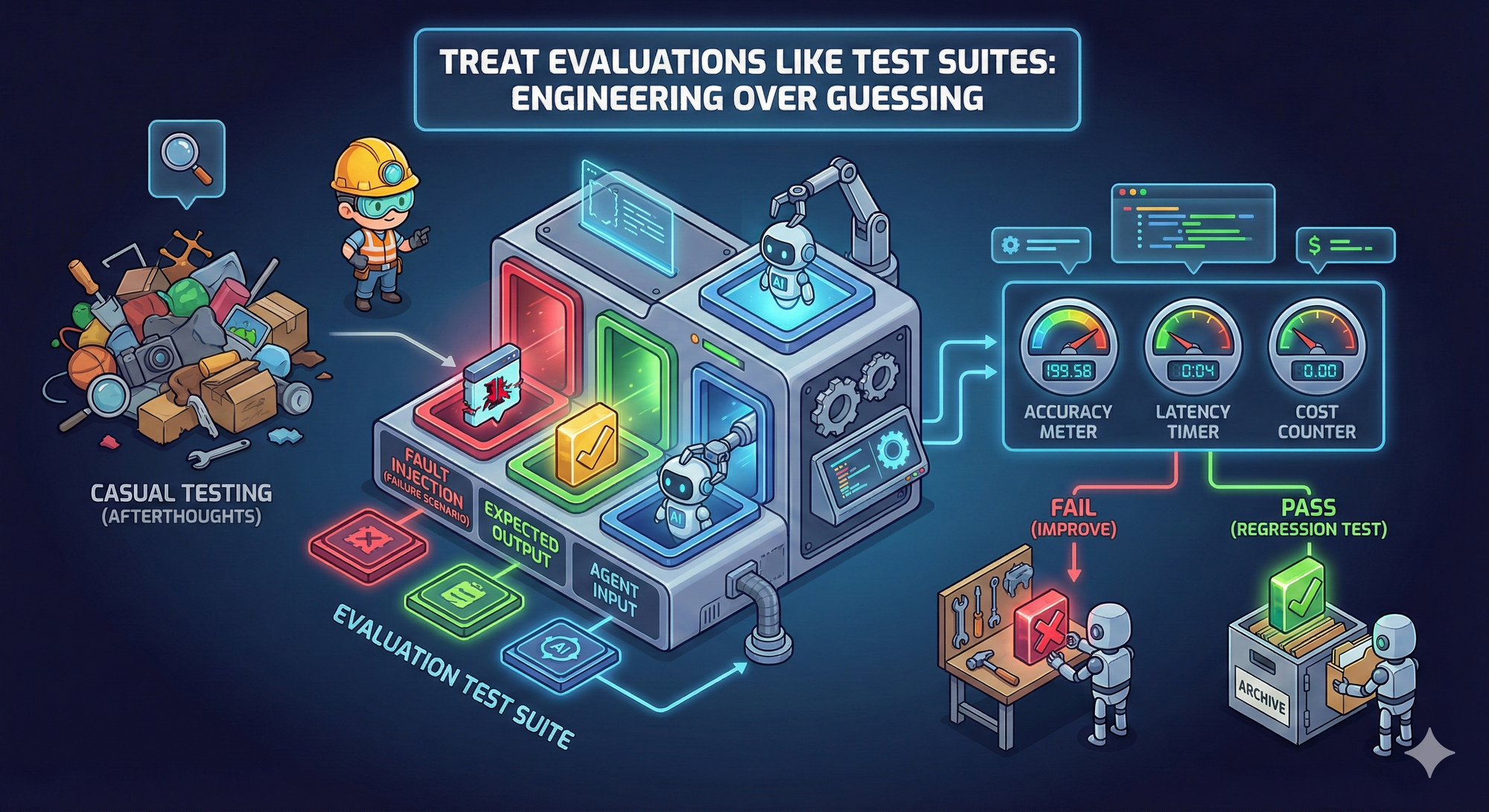
1. Treat evaluations like test suites, not afterthoughts 🧪
Testing an agent casually is risky. Running a few prompts and eyeballing the answers does not tell you whether the system is dependable. Just like traditional software relies on unit and integration tests, agents need structured evaluations.
Each realistic failure scenario should behave like a test case. Introduce a fault, run the agent, and verify whether it identifies the correct root cause. Measure not only accuracy, but also latency and cost. Failing scenarios show you exactly where to improve, while passing ones become regression tests that protect quality over time. Without evaluations, you’re guessing. With evaluations, you’re engineering.
2. Keep feedback loops short 🔁
Slow testing kills progress. If every experiment takes thirty or forty minutes to validate, developers stop testing thoroughly. They bundle many changes together and hope nothing breaks.
Fast feedback changes behavior completely. When scenarios can be rerun in minutes, teams experiment more, iterate faster, and ship safer updates. Practical steps like reusing long-running environments, testing only the affected part of the agent, and enabling local execution dramatically reduce wait times. The shorter the loop, the better the product.

3. Visualize the agent’s reasoning 🔍
When an agent produces the wrong result, the mistake rarely happens at the final step. It usually occurs earlier, during data gathering or tool usage. Looking only at the final output hides the real cause.
You need visibility into the entire trajectory: what data the agent accessed, which tools it called, what it ignored, and how context evolved. Once you can trace every step, patterns become obvious. Maybe it pulled too much noise, consumed too many tokens, or followed irrelevant signals. Observability turns debugging from guesswork into analysis.

4. Make intentional changes, not emotional fixes 📏
It’s easy to tweak prompts until one failing case suddenly works. That feels like progress, but it often introduces hidden regressions elsewhere. This is confirmation bias.
Instead, treat improvements scientifically. Define a baseline, decide which metrics matter, and establish clear success criteria before changing anything. After modifications, compare results against the same metrics. If the numbers don’t improve, reject the change. Production systems reward measurable improvements, not clever tricks.
5. Learn from real production usage 📈
Test environments are controlled and predictable. Real users are not. Production brings unexpected architectures, edge cases, and traffic patterns you never planned for.
Regularly reviewing real-world runs reveals what customers actually experience. These observations uncover new failure modes and help you design better evaluations. Nothing sharpens intuition faster than watching your system operate in reality. Production feedback is irreplaceable.

The mindset shift that matters 🧠
The biggest mistake teams make is treating agents as “smart assistants.” In practice, they are software systems, and software systems demand testing, monitoring, and disciplined iteration. Success does not come from bigger models alone. It comes from better engineering processes.
Final thoughts
Anyone can build an impressive AI demo in a weekend. Building something reliable enough to handle real incidents every day is much harder. If you want your DevOps agent to earn trust, focus on fundamentals: evaluate rigorously, shorten feedback loops, visualize behavior, measure changes objectively, and learn continuously from production. That’s how prototypes become dependable products.
“Smart agents impress in demos. Reliable agents earn trust in production.”