AI-Powered DevOps: Streamline Software Delivery and SRE Efficiency
How is AI transforming DevOps? Discover how AI-powered automation streamlines software delivery, improves observability, and boosts SRE efficiency.

A deployment goes live. Dashboards start shifting. Alerts trickle in.
Nothing is broken yet, but something is off.
Now imagine systems that detect these early signals, correlate them with recent changes, and surface likely causes before the first incident channel lights up.
That quiet shift from reactive operations to predictive reliability is where AI is beginning to reshape DevOps and SRE.
In this post, we’ll dive into how AI-powered DevOps is reshaping software delivery and lifting Site Reliability Engineering (SRE) from firefighting to strategic system guardianship. Expect clear explanations, practical patterns, and a bit of wit, because who says reliability can’t be fun? 😄
Why AI + DevOps = A Match Made in Binary Heaven
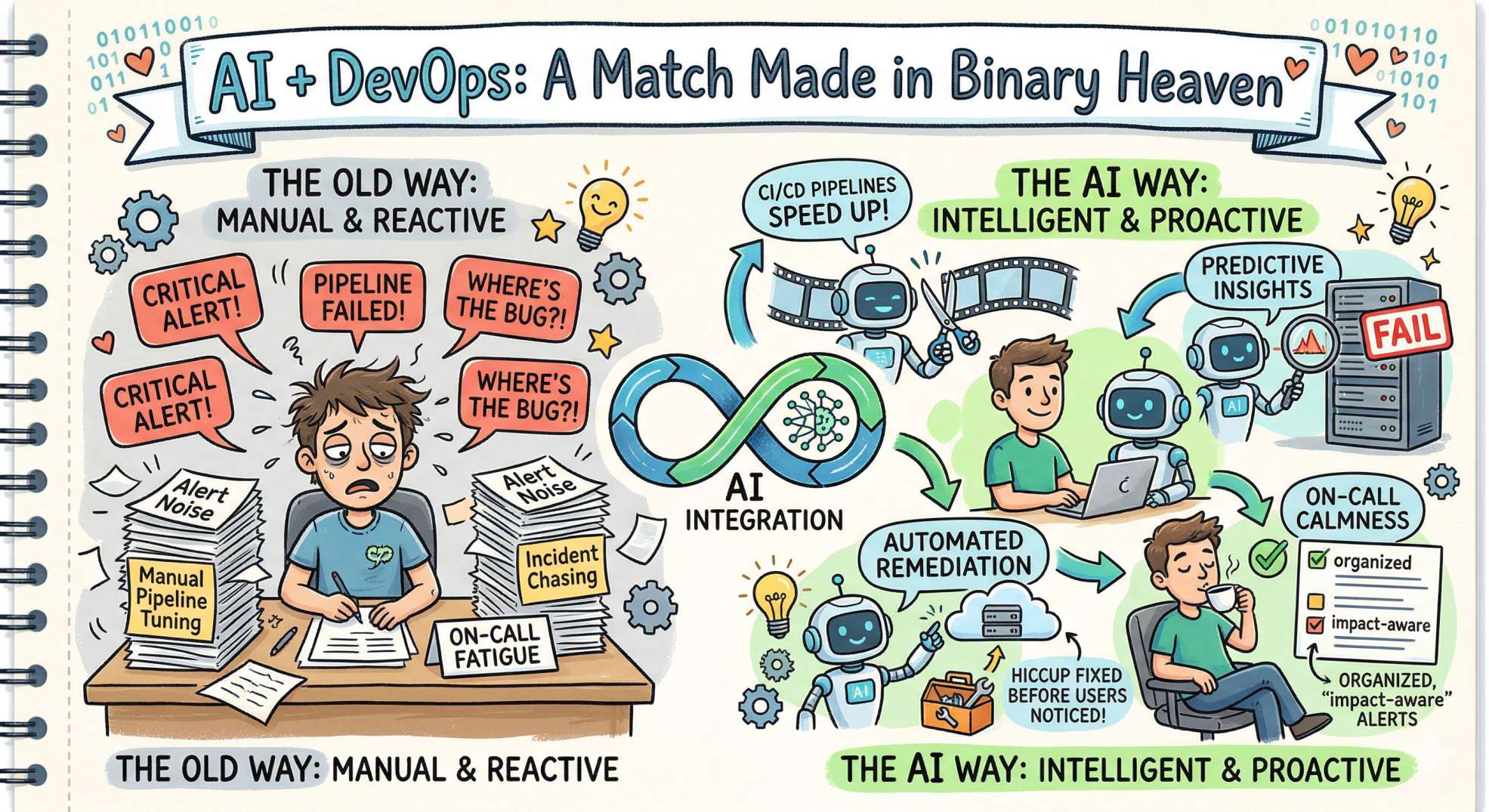
DevOps is about culture, automation, and continuous improvement. Add AI to that mix, and you get intelligent automation, predictive insights, and less time doing repetitive labor. Instead of manually chasing incidents or tuning pipelines by hand, AI can spot patterns, prioritize work, and execute remediation, sometimes before users even notice a hiccup.
Benefits at a glance:
- CI/CD pipelines spend less time executing unnecessary work
- Reliability improves as anomalies are surfaced before thresholds fail
- On-call fatigue drops because repetitive investigation steps become automated
- Alert prioritization becomes impact-aware rather than volume-driven
Core Areas Where AI Amplifies DevOps & SRE
1. Smarter CI/CD Pipelines
AI can predict flaky tests, prioritize test suites based on code changes, and optimize pipeline execution to reduce feedback time. Imagine a pipeline that runs only the tests most likely to fail for your specific change. Your builds finish faster, and developers get feedback sooner. 🏁
2. Predictive Observability
Observability platforms augmented with ML can spot anomalous behavior before thresholds are breached. These systems learn normal patterns for metrics, traces, and logs, then surface only the signals that matter. Say goodbye to noisy dashboards and hello to clarity. 👀
Ask yourself: If your dashboards went silent tomorrow except for signals that truly mattered, how would your incident response habits change?
3. Incident Detection and Triage
Natural language processing (NLP) and clustering algorithms help group related alerts, summarize root causes, and even suggest runbook steps. Instead of a sea of alerts, SREs get succinct, actionable incident summaries. Less panic, more problem-solving. 🧠
4. Automated Remediation
AI-driven playbooks can trigger safe, tested remediation steps, such as restarting services, scaling resources, or rolling back deployments, with human approval or autonomously within guardrails. Think of it as a skilled autopilot for stability. ✈️
5. Capacity Planning & Cost Optimization
Forecasting models can predict traffic spikes, suggest right-sizing recommendations, and identify underutilized resources. Lower cloud bills + fewer surprises = happy finance and engineering teams. 💰
Real-World Use Cases
- Test selection: Use historical test outcomes and code-change diff analysis to run a minimal set of high-risk tests.
- Anomaly detection: ML flags latency drift across services before SLAs are impacted.
- Automated rollback: System detects increased error rates caused by a deployment and triggers an atomic rollback.
- Root-cause hints: NLP summarizes recent deployments, config changes, and correlated logs to point engineers to likely causes.
- ChatOps assistant: An intelligent bot answers “Why is my service slow?” by querying traces and metrics in natural language.
These capabilities do not emerge from a single platform but from a layered ecosystem that allows systems to observe, reason, and act across delivery and runtime environments.
Key Technologies & Tools
Want the quick map? Here are pillars and tooling directions that teams commonly use to enable AI-driven DevOps:
- Observability platforms with ML features (some vendors provide built-in anomaly detection)
- Log and trace analysis with vector search or embedding-based similarity
- CI/CD orchestration combined with ML models for test selection
- Runbook automation and orchestration tools that accept programmatic triggers
- ChatOps / conversational AI for workflows and incident communication
Popular tools and libraries span open-source and commercial space — think Prometheus, Grafana, OpenTelemetry, Elastic, Sentry, ArgoCD, Jenkins/X, and newer AI-capable platforms that layer ML over logs and metrics. You can also build custom models with TensorFlow, PyTorch, or use managed ML services.
How to Start: A Practical Roadmap

Adopting AI in DevOps doesn’t mean flipping a switch. Here’s a pragmatic rollout plan you can follow (and pretend you invented):
Step 1: Bake Observability into Everything
- Collect structured logs, traces, and rich metrics with consistent naming.
- Instrument code and services with OpenTelemetry or vendor SDKs.
Step 2: Clean Data = Useful AI
- Centralize, normalize, and label historical incidents and test outcomes.
- Fix noisy alerts and inconsistent metric tags before modeling.
Step 3: Start Small with High-ROI Problems
- Use ML for test selection or anomaly detection where gains are measurable.
- Run pilots and measure savings: pipeline time, MTTR, or alert reduction.
Step 4: Build Trust with Human-in-the-Loop
- Keep an SRE or engineer in the decision loop for early automation phases.
- Surface confidence scores and rationale for automated suggestions.
Step 5: Automate Safely
- Start with remediation suggestions, then move to semi-automated actions, and finally, safe autonomous actions with rollback strategies and canaries.
Step 6 Measure & Iterate
- Track MTTR, deployment frequency, test runtime, and alert noise as KPIs.
- Refine models and policies using feedback loops and incident postmortems.
Common Challenges (and How to Beat Them)
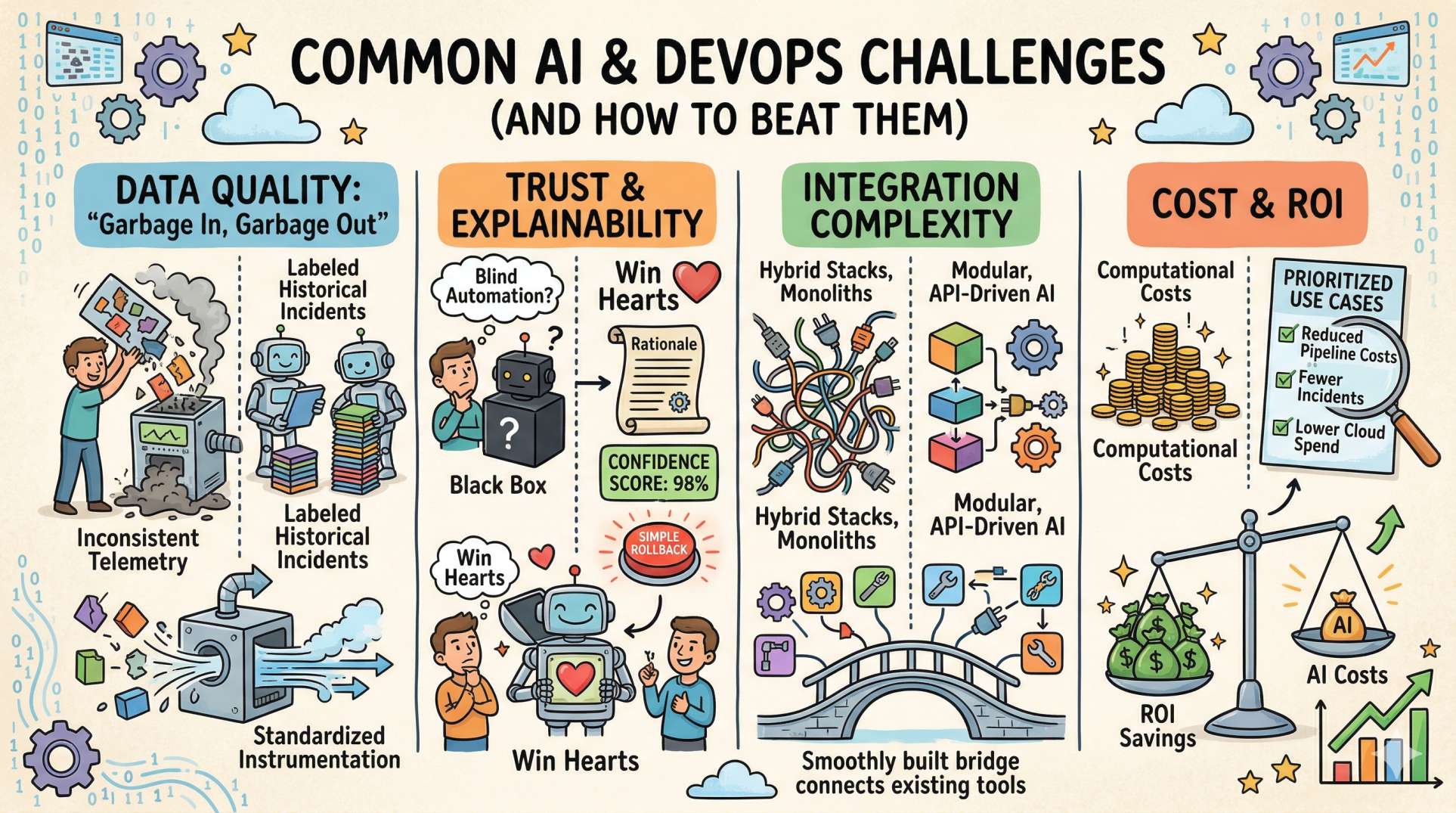
Data Quality
Garbage in, garbage out. Low-quality, inconsistent telemetry will make ML models useless. Standardize instrumentation and invest time in labeling historical incidents.
Trust & Explainability
Engineers resist blind automation. Provide rationale for predictions, confidence scores, and simple rollback paths to build confidence. A transparent system wins hearts (and on-call shifts). ❤
Integration Complexity
Many orgs have hybrid stacks. Use modular, API-driven AI components that build on existing tools rather than replacing everything at once.
Cost & ROI
ML can introduce computational costs. Prioritize use cases with clear savings (e.g., reduced pipeline costs, fewer incidents, lower cloud spend).
Best Practices for AI-Driven DevOps
- Keep humans in the loop early; automation without oversight is risky.
- Start with explainable models and gradually incorporate more complex approaches.
- Track business impact; tie technical improvements to customer-facing KPIs.
- Run chaos experiments to validate AI-driven remediation under controlled failure modes.
- Document runbooks and model behavior so on-call teams have a reliable playbook.
Mini Case Study: “The Pipeline That Learned to Skip”
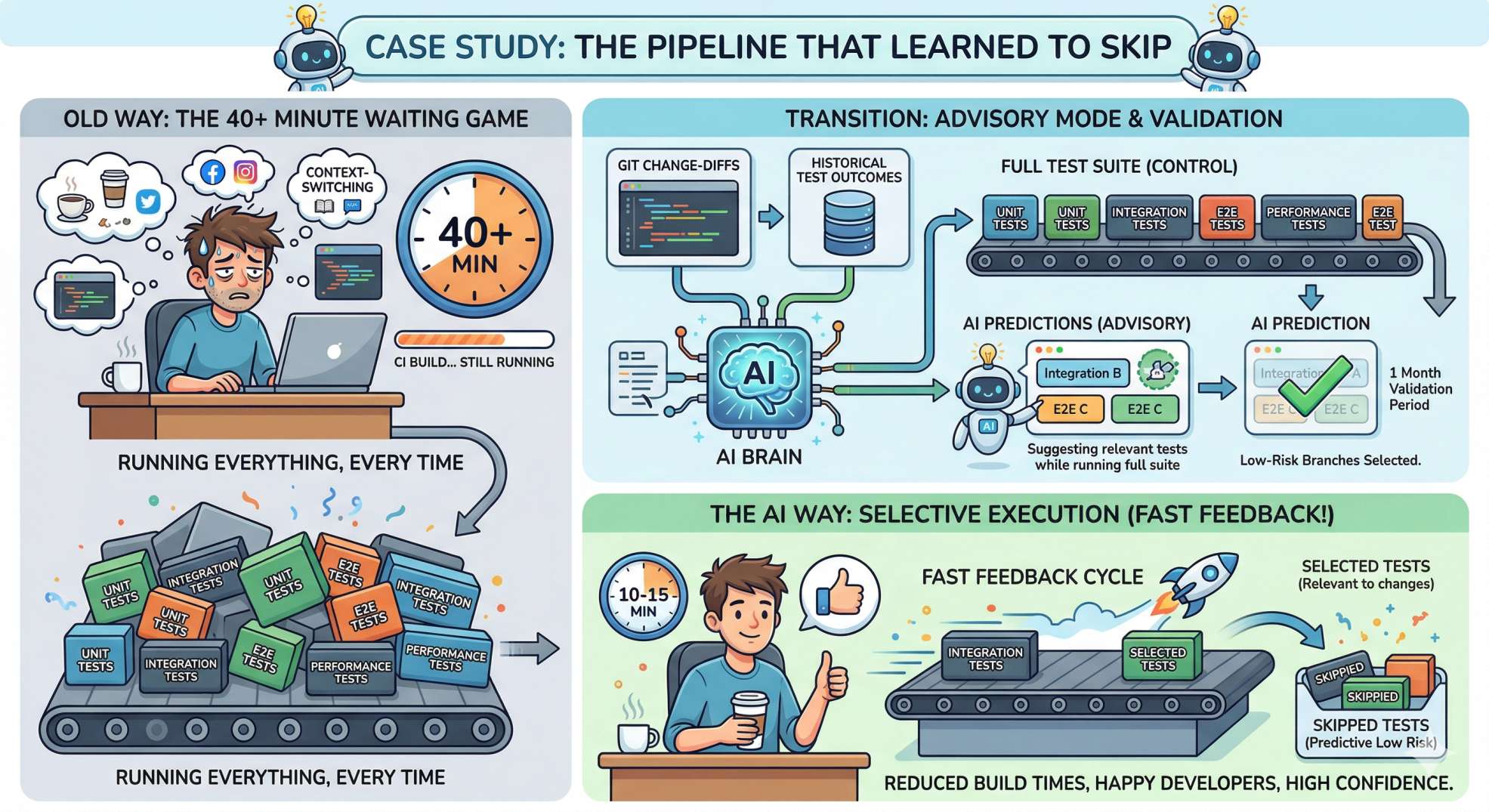
Imagine a mid-size product company plagued by long build times. Developers waited 40+ minutes for CI feedback, leading to context-switching and frustration. The team trained a model to predict which tests fail based on change-diffs and historical test outcomes. They started by running the model in advisory mode: suggesting tests to run while still executing full suites. After a month of validation, they enabled selective execution for low-risk branches.
Result: average CI time dropped by 60%, and developers got back precious brain cycles. Productivity went up, and the on-call pager calmed down a notch.
Ethics & Governance
AI systems in operations must be governed:
- Audit decisions made by models (who triggered a rollback and why?).
- Maintain data privacy for logs and traces; mask secrets and PII.
- Set guardrails for autonomous actions, including human override and post-action review.
Looking Ahead: The Next 3–5 Years
Expect AI to become a standard layer in the DevOps stack rather than an experimental add-on. We’ll see:
- Ubiquitous ML-based anomaly detection embedded in observability tools
- Smarter runbooks that self-update from incident resolutions
- Conversational SRE assistants that can orchestrate fixes across systems
- More cross-team alignment as AI exposes systemic issues (architecture, testing gaps)
As AI matures, SRE roles will evolve: less repetitive toil, more systems thinking, and greater focus on reliability engineering at scale. Think of SREs as orchestral conductors, while AI manages the metronome. 🎻🤖
Ask yourself: Which part of your current workflow still feels reactive rather than anticipatory?
Wrap-Up: Your First Two Actions Today
Ready to get started? Don’t try to boil the ocean. Two small steps you can take right now:
- Audit your telemetry: Ensure metrics, logs, and traces are consistent and centralized.
- Pick one high-impact pilot: Test-suite optimization or anomaly detection are great first candidates.
AI-powered DevOps isn’t magic; it’s engineering plus data plus iteration. But when done right, it turns a reactive ops team into a proactive reliability machine. Want more practical guides, templates, or example playbooks? Hover over to DevOps Inside and let’s continue building smarter delivery together. 🚀
Thanks for reading; may your pipelines be fast and your incidents brief! ✨
The future of DevOps is not autonomous operations.
It is augmented operations.